Tips - Analyze
1. Dataset 'Tips' (Seaborn)
2. Analyse Univariée - Variable discrète 'sex'
3. Analyse Univariée - Variable continue 'tip'
Documentation pour l'Analyse Univariée
4. Analyse Multivariée - Entre 2 variables discrètes 'smoker' et 'sex'
5. Analyse Multivariée - Variable discrète / Variable continue
6. Analyse Multivariée - Entre deux variables continues 'tip' et 'total_bill'
Documentation sur Analyses Multivariées - Variables discrètes ou continues
2. Analyse Univariée - Variable discrète 'sex'
3. Analyse Univariée - Variable continue 'tip'
Documentation pour l'Analyse Univariée
4. Analyse Multivariée - Entre 2 variables discrètes 'smoker' et 'sex'
5. Analyse Multivariée - Variable discrète / Variable continue
6. Analyse Multivariée - Entre deux variables continues 'tip' et 'total_bill'
Documentation sur Analyses Multivariées - Variables discrètes ou continues
1. Dataset 'Tips' (Seaborn)
sns.load_dataset('tips')
df.head()
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
df.describe()
total_bill tip size count 244.000000 244.000000 244.000000 mean 19.785943 2.998279 2.569672 std 8.902412 1.383638 0.951100 min 3.070000 1.000000 1.000000 25% 13.347500 2.000000 2.000000 50% 17.795000 2.900000 2.000000 75% 24.127500 3.562500 3.000000 max 50.810000 10.000000 6.000000
Quelles sont les variables discrètes et les variables continues ?
→
Variables discrètes : 'sex', 'smoker', 'day', 'time' et 'size'
Variables continues : 'total_bill' et 'tip'
Variables continues : 'total_bill' et 'tip'
2. Analyse Univariée - Variable discrète 'sex'
Calcul des effectifs
df['sex'].value_counts(normalize=False, sort=True, ascending=False)
sex Male 157 Female 87 Name: count, dtype: int64
→
157 des personnes de l'échantillon sont des hommes, 87 personnes sont des femmes
df['sex'].value_counts(normalize=True, sort=True, ascending=False)
sex Male 0.643443 Female 0.356557 Name: proportion, dtype: float64
→
64% des personnes de l'échantillon sont des hommes, 36% des personnes sont des femmes
Avec la librairie Pandas
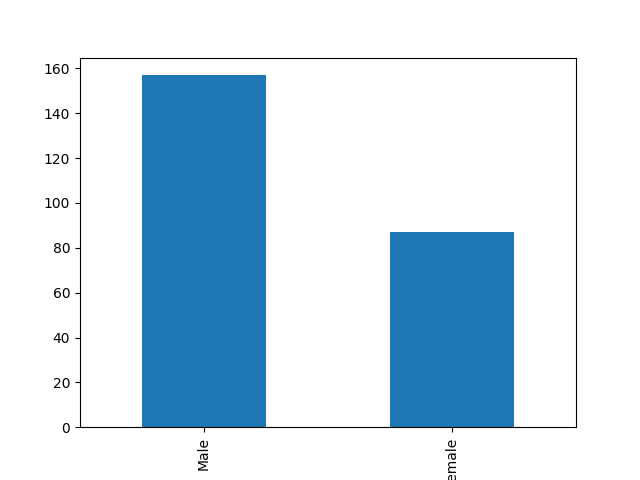
df['sex'].value_counts(normalize=False, sort=True, ascending=False).plot(kind='bar')
Avec la librairie Seaborn
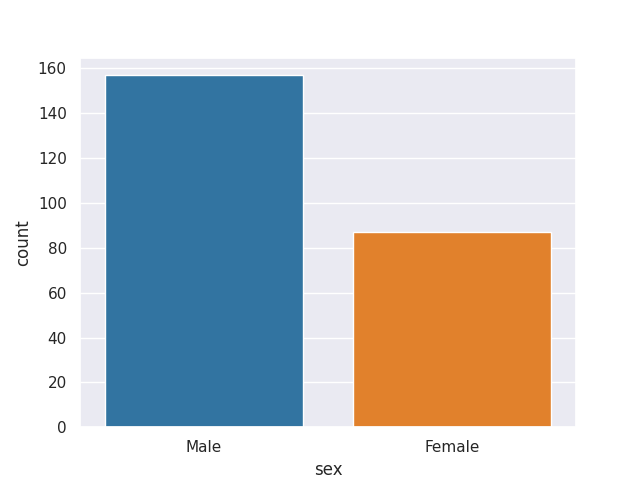
sns.countplot(data=df, x='sex')
3. Analyse Univariée - Variable continue 'tip'
df['tip'].describe()
count 244.000000 mean 2.998279 std 1.383638 min 1.000000 25% 2.000000 50% 2.900000 75% 3.562500 max 10.000000 Name: tip, dtype: float64
df['tip'].mean()
2.99827868852459
df['tip'].median()
2.9
df['tip'].var()
1.914454638062471
df['tip'].std()
1.3836381890011822
df['tip'].min()
1.0
df['tip'].max()
10.0
Histogramme avec la librairie Pandas (20 intervalles)
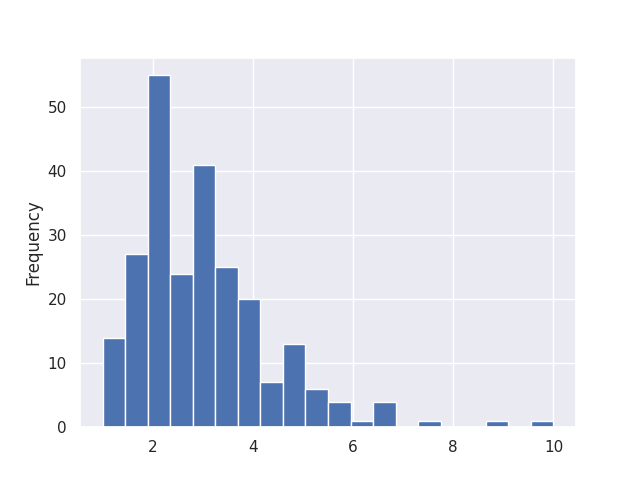
df['tip'].plot(kind='hist', bins=20)
Histogramme avec la librairie Seaborn (20 intervalles)
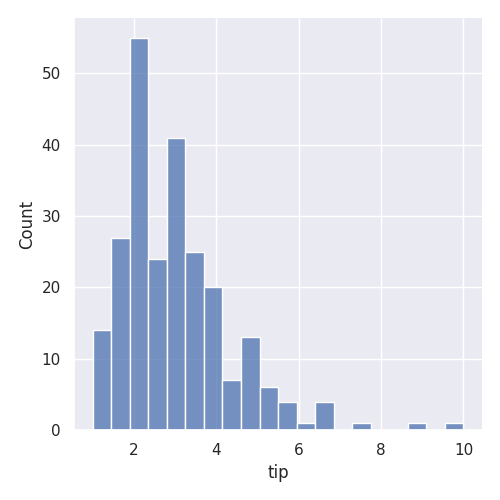
sns.displot(data=df, x='tip', bins=20)
bosplot avec la librairie Pandas
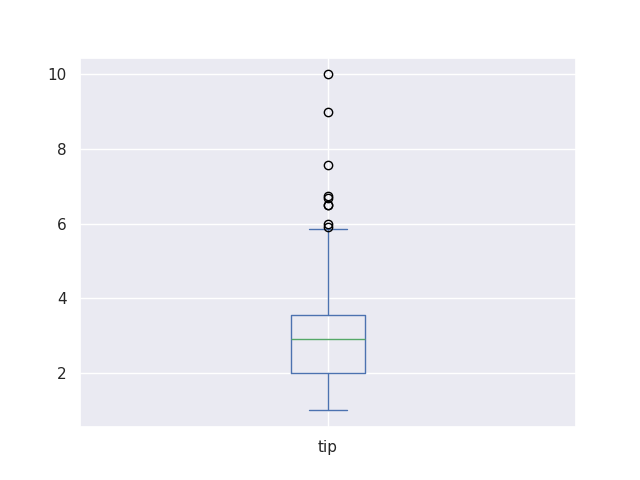
df['tip'].plot(kind='box')
boxplot avec la librairie Seaborn

fig, ax = plt.subplots(figsize=(10, 2))
sns.catplot(data=df, y='tip', kind='box')
Documentation pour l'Analyse Univariée
Tous les graphiques possibles avec Pandas
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
Générer un Histograme avec Seaborn
https://seaborn.pydata.org/generated/seaborn.displot.html#seaborn.displot
https://seaborn.pydata.org/generated/seaborn.displot.html#seaborn.displot
Générer une BoxPlot avec Pandas
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.box.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.box.html
Générer une BoxPlot avec Seaborn (Catplot)
https://seaborn.pydata.org/generated/seaborn.catplot.html#seaborn.catplot
https://seaborn.pydata.org/generated/seaborn.catplot.html#seaborn.catplot
4. Analyse Multivariée - Entre 2 variables discrètes 'smoker' et 'sex'
Table de contingence
pd.crosstab(df['sex'], df['smoker'])
smoker Yes No sex Male 60 97 Female 33 54
Table de contingence normalisée
pd.crosstab(df['sex'], df['smoker'], normalize=True)
smoker Yes No sex Male 0.245902 0.397541 Female 0.135246 0.221311
Heatmap 'sex' / 'smoker'
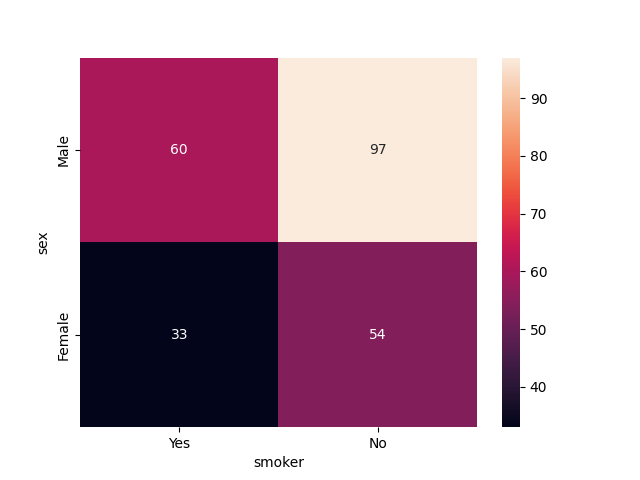
sns.heatmap(pd.crosstab(df['sex'], df['smoker']), annot=True)
Heatmap 'size' / 'day'
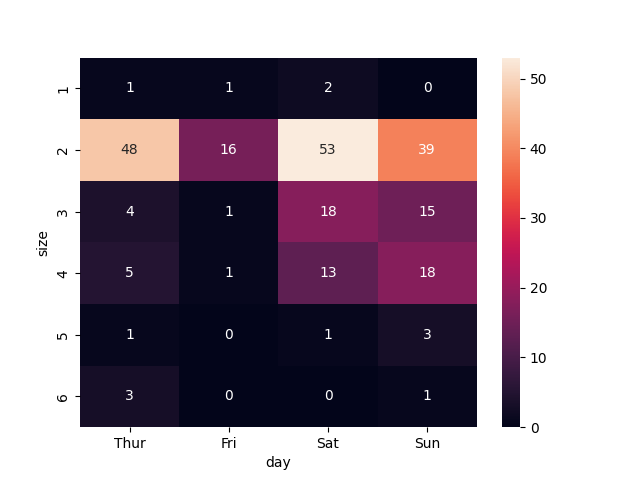
sns.heatmap(pd.crosstab(df['size'], df['day']), annot=True)
5. Analyse Multivariée - Variable discrète / Variable continue
df.groupby('sex')['tip'].describe()
count mean std min 25% 50% 75% max sex Male 157.0 3.089618 1.489102 1.0 2.0 3.00 3.76 10.0 Female 87.0 2.833448 1.159495 1.0 2.0 2.75 3.50 6.5
df.groupby('sex')['tip'].mean()
sex Male 3.089618 Female 2.833448 Name: tip, dtype: float64
df.groupby('sex')['tip'].median()
sex Male 3.00 Female 2.75 Name: tip, dtype: float64
Histogramme 'sex' <-> 'tip' avec la librairie Pandas
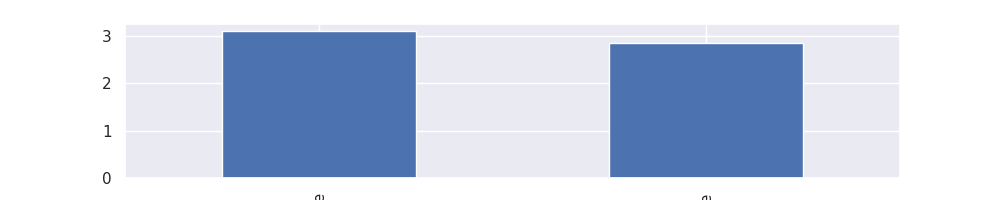
df.groupby('sex')['tip'].mean().plot(kind='bar')
Histogramme 'sex' <-> 'tip' avec la librairie Seaborn
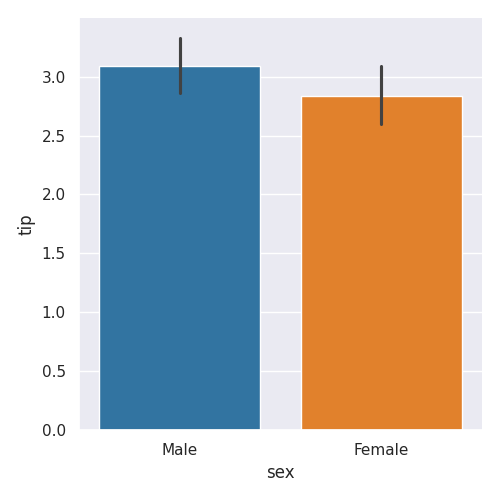
sns.catplot(data=df, x='sex', y='tip', kind='bar')
Histogramme avec la librairie Seaborn
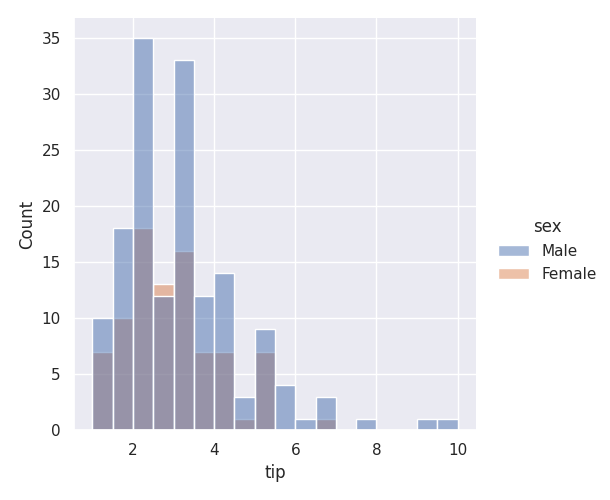
sns.displot(data=df, x='tip', hue='sex')
Boxplot avec la librairie Seaborn
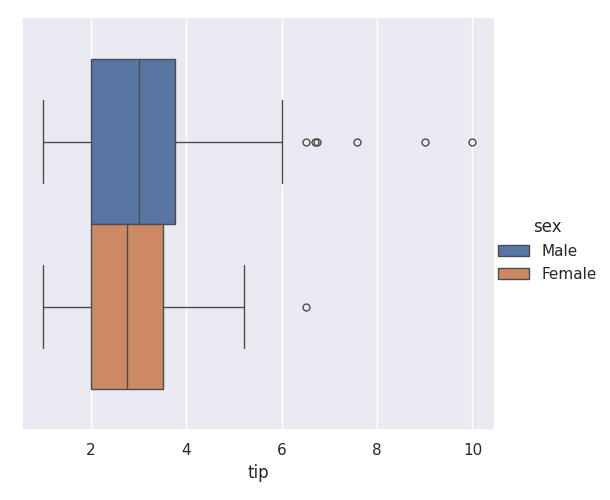
sns.catplot(data=df, x='tip', hue='sex', kind='box')
6. Analyse Multivariée - Entre deux variables continues 'tip' et 'total_bill'
Scatter plot - Nuage de points (Pandas)
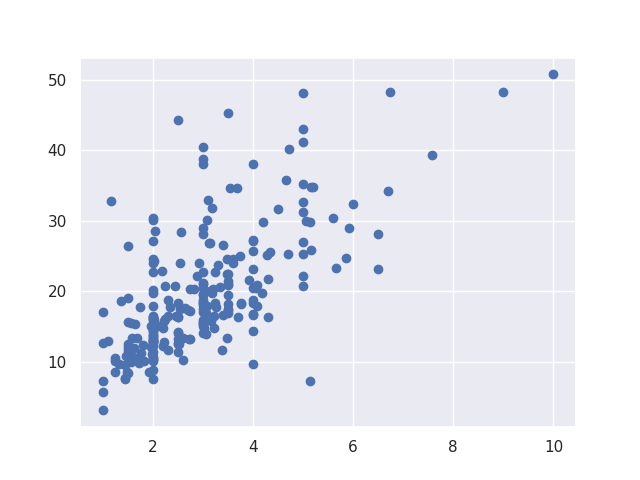
plt.scatter(df['tip'], df['total_bill'])
Scatter plot - Nuage de points (Seaborn)
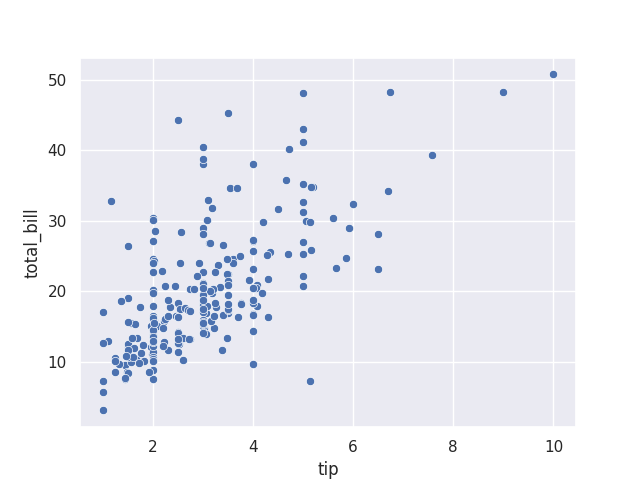
sns.scatterplot(data=df, x='tip', y='total_bill')