Titanic - Analyze
1. Dataset 'Titanic' (Seaborn)
sns.load_dataset('titanic')
df
survived pclass sex age ... deck embark_town alive alone 0 0 3 male 22.0 ... NaN Southampton no False 1 1 1 female 38.0 ... C Cherbourg yes False 2 1 3 female 26.0 ... NaN Southampton yes True 3 1 1 female 35.0 ... C Southampton yes False 4 0 3 male 35.0 ... NaN Southampton no True .. ... ... ... ... ... ... ... ... ... 886 0 2 male 27.0 ... NaN Southampton no True 887 1 1 female 19.0 ... B Southampton yes True 888 0 3 female NaN ... NaN Southampton no False 889 1 1 male 26.0 ... C Cherbourg yes True 890 0 3 male 32.0 ... NaN Queenstown no True [891 rows x 15 columns]
→
891 lignes et 15 colonnes
df.dropna()
survived pclass sex age ... deck embark_town alive alone 1 1 1 female 38.0 ... C Cherbourg yes False 3 1 1 female 35.0 ... C Southampton yes False 6 0 1 male 54.0 ... E Southampton no True 10 1 3 female 4.0 ... G Southampton yes False 11 1 1 female 58.0 ... C Southampton yes True .. ... ... ... ... ... ... ... ... ... 871 1 1 female 47.0 ... D Southampton yes False 872 0 1 male 33.0 ... B Southampton no True 879 1 1 female 56.0 ... C Cherbourg yes False 887 1 1 female 19.0 ... B Southampton yes True 889 1 1 male 26.0 ... C Cherbourg yes True [182 rows x 15 columns]
→
/!\ dropna() => 182 lignes et 15 colonnes
→
709 lignes avec au moins un NaN
2. Diagnostiquer le dataset
Y-a-t-il des valeurs manquantes ?
Combien ?
Comment sont-elles réparties ?
Filtrer le jeu de données
Analyser les entrées pour tenter de comprendre pourquoi ces valeurs sont NaN
Combien ?
Comment sont-elles réparties ?
Filtrer le jeu de données
Analyser les entrées pour tenter de comprendre pourquoi ces valeurs sont NaN
df.isna()
survived pclass sex age ... deck embark_town alive alone 0 False False False False ... True False False False 1 False False False False ... False False False False 2 False False False False ... True False False False 3 False False False False ... False False False False 4 False False False False ... True False False False .. ... ... ... ... ... ... ... ... ... 886 False False False False ... True False False False 887 False False False False ... False False False False 888 False False False True ... True False False False 889 False False False False ... False False False False 890 False False False False ... True False False False [891 rows x 15 columns]
Nombre de NaN par colonne
df.isna().sum(axis=0)
survived 0 pclass 0 sex 0 age 177 sibsp 0 parch 0 fare 0 embarked 2 class 0 who 0 adult_male 0 deck 688 embark_town 2 alive 0 alone 0 dtype: int64
Heatmap
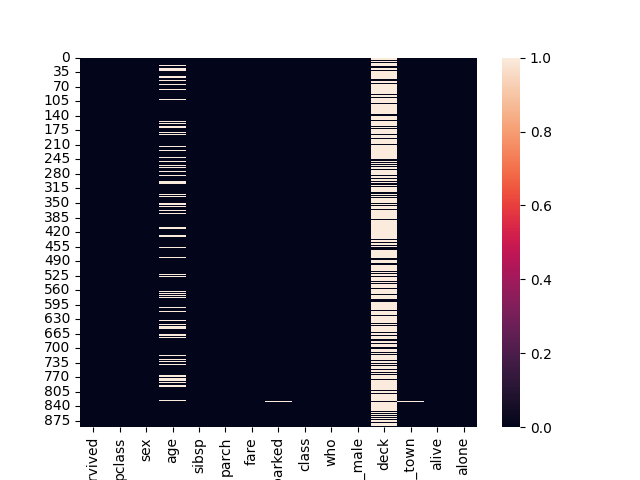
sns.heatmap(df.isna())
→
Colonne 'deck' est constituée de NaN. => Est-ce que cette variable est intéressante pour notre analyse ?
Colonne 'age' => élimine la colonne ou élimine les lignes ? => tester les deux.
Colonne 'age' => élimine la colonne ou élimine les lignes ? => tester les deux.
df.isna().any()
survived False pclass False sex False age True sibsp False parch False fare False embarked True class False who False adult_male False deck True embark_town True alive False alone False dtype: bool
Lignes contenant un NaN
df.isna().any(axis=1)
0 True
1 False
2 True
3 False
4 True
...
886 True
887 False
888 True
889 False
890 True
Length: 891, dtype: bool
Avec Boolean Indexing
df[df.isna().any(axis=1)]
survived pclass sex age ... deck embark_town alive alone 0 0 3 male 22.0 ... NaN Southampton no False 2 1 3 female 26.0 ... NaN Southampton yes True 4 0 3 male 35.0 ... NaN Southampton no True 5 0 3 male NaN ... NaN Queenstown no True 7 0 3 male 2.0 ... NaN Southampton no False .. ... ... ... ... ... ... ... ... ... 884 0 3 male 25.0 ... NaN Southampton no True 885 0 3 female 39.0 ... NaN Queenstown no False 886 0 2 male 27.0 ... NaN Southampton no True 888 0 3 female NaN ... NaN Southampton no False 890 0 3 male 32.0 ... NaN Queenstown no True [709 rows x 15 columns]
Index des lignes avec au moins un NaN
na_index = df[df.isna().any(axis=1)].index
Index([ 0, 2, 4, 5, 7, 8, 9, 12, 13, 14,
...
878, 880, 881, 882, 883, 884, 885, 886, 888, 890],
dtype='int64', length=709)
3. Eliminer les NaN avec dropna
Objectif: Conserver le plus de données possibles
Elimine la colonne 'deck' et met à jour le dataframe
df.drop(labels='deck', axis=1, inplace=1)
survived pclass sex age ... adult_male embark_town alive alone 0 0 3 male 22.0 ... True Southampton no False 1 1 1 female 38.0 ... False Cherbourg yes False 2 1 3 female 26.0 ... False Southampton yes True 3 1 1 female 35.0 ... False Southampton yes False 4 0 3 male 35.0 ... True Southampton no True .. ... ... ... ... ... ... ... ... ... 886 0 2 male 27.0 ... True Southampton no True 887 1 1 female 19.0 ... False Southampton yes True 888 0 3 female NaN ... False Southampton no False 889 1 1 male 26.0 ... True Cherbourg yes True 890 0 3 male 32.0 ... True Queenstown no True [891 rows x 14 columns]
Paramètres : dropna(how='any') ou dropna(thresh=12)